Appearance
百度PaddlePaddle重磅发布!0.9B超轻量多模态模型PaddleOCR-VL,文档解析性能SOTA,小参数如何逆袭大模型?
在当今的大模型(LLM)时代,文档解析(Document Parsing) 已成为连接非结构化数据与智能应用的“最后一公里”。无论是RAG(检索增强生成)系统,还是智能文档处理助手,如何精准地从复杂的PDF、扫描件中提取出文本、表格、公式和图表,并还原其阅读顺序,始终是一个巨大的挑战。
过去,我们要么依赖复杂的传统OCR流水线,维护成本高且容易累积误差;要么投向通用多模态大模型(如GPT-4o, Qwen-VL)的怀抱,但面临着推理成本高昂、速度慢以及“幻觉”频发的问题。
有没有一种既轻量高效,又能媲美甚至超越顶尖大模型性能的解决方案?
近日,百度PaddlePaddle团队 交出了一份令人惊艳的答卷——PaddleOCR-VL。这项工作提出了一种基于0.9B参数的超轻量级视觉语言模型方案,在保持极低资源消耗的同时,在多语言文档解析任务上实现了SOTA性能。
今天,我们就来深度拆解这篇论文,看看PaddleOCR-VL是如何以小博大,重新定义文档解析新标准的。👇
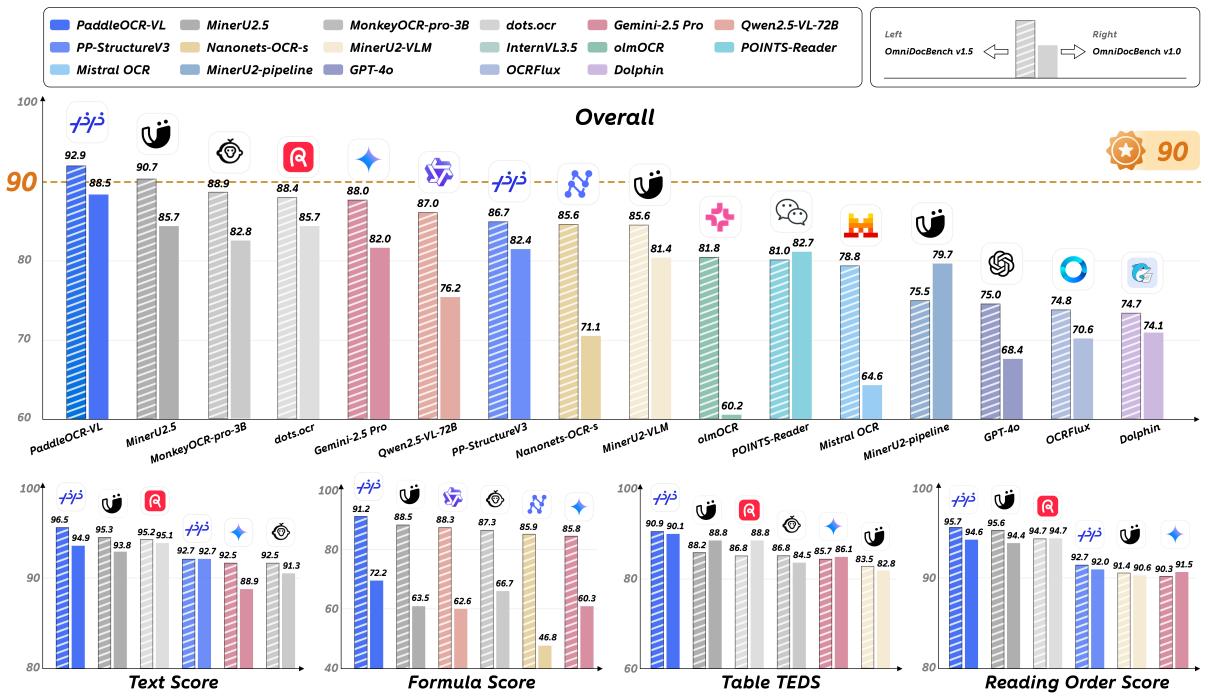 图1:PaddleOCR-VL 在 OmniDocBench v1.0 和 v1.5 上的性能表现
图1:PaddleOCR-VL 在 OmniDocBench v1.0 和 v1.5 上的性能表现
🚀 核心洞见:为什么我们需要PaddleOCR-VL?
在深入技术细节之前,我们需要理解当前文档处理领域的痛点。
传统的流水线方法(Pipeline Approaches) 就像是一条精密的工业生产线,版面分析、文本检测、文本识别、表格还原……每个环节都有专门的模型。虽然可控性强,但一旦前一个环节出错(比如把表格切成了文本),错误就会无限放大。而且,面对图文混排、复杂公式等高难度场景,传统OCR往往力不从心。
另一边,端到端的多模态大模型(End-to-End VLMs) 试图用一个模型解决所有问题。它们通过“看”图直接生成Markdown。然而,这种方法有两个致命弱点:
- “贵”且“慢”:处理长文档时,大模型的长序列生成会导致巨大的计算开销和延迟。
- 幻觉与排序难题:在面对多栏排版或密集文本时,大模型容易“眼花”,搞错阅读顺序,甚至编造内容。
PaddleOCR-VL 的破局思路非常巧妙: 它没有盲目追求“大”,而是选择了“解耦”与“专用”。它将复杂的文档解析分解为两个核心阶段:版面分析(Layout Analysis) 和 元素级识别(Element-level Recognition),并专门为此设计了高效的模型架构。
🏗️ 架构揭秘:精妙的二阶段设计
PaddleOCR-VL 的整体架构设计体现了极强的工程实用主义哲学。它不是一个单一的黑盒模型,而是一个协同工作的系统。
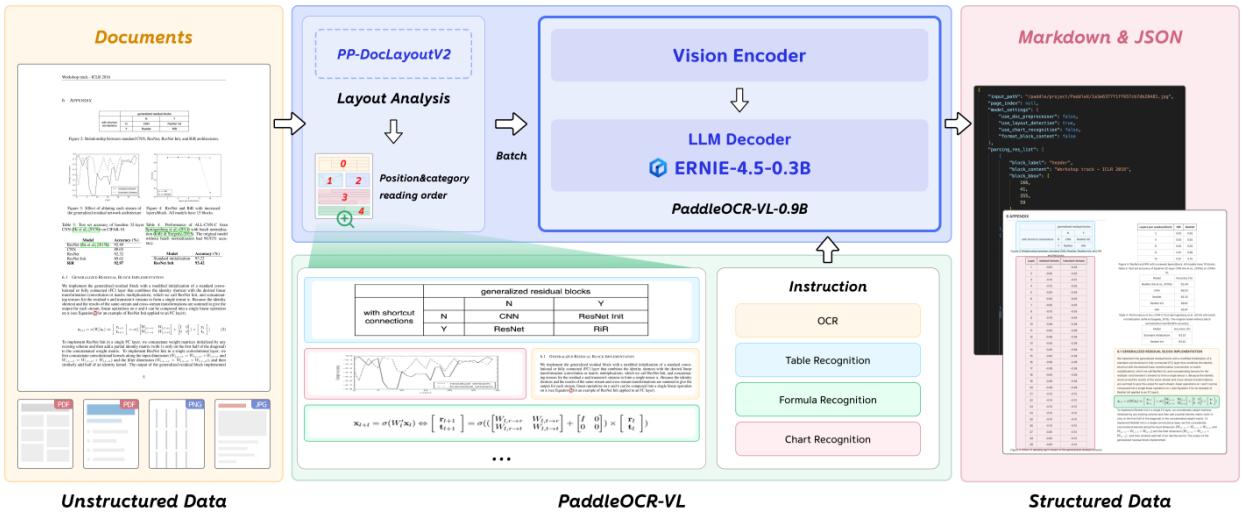 图2:PaddleOCR-VL 的整体架构概览
图2:PaddleOCR-VL 的整体架构概览
如上图所示,整个流程清晰明了:
- PP-DocLayoutV2:负责“看骨架”,定位文档中的文本块、表格、公式、图表,并确定它们的阅读顺序。
- PaddleOCR-VL-0.9B:负责“填血肉”,根据定位到的区域,精准识别内容。
- 后处理:将结果组装成结构化的Markdown或JSON。
这种设计最大的好处是:规避了端到端VLM在长文档上的不稳定性,同时利用了VLM在复杂元素识别上的强大能力。
1. 版面分析:PP-DocLayoutV2 —— 给文档“定坐标”
在第一阶段,团队没有直接使用VLM,而是设计了一个轻量级的专用模型 PP-DocLayoutV2。
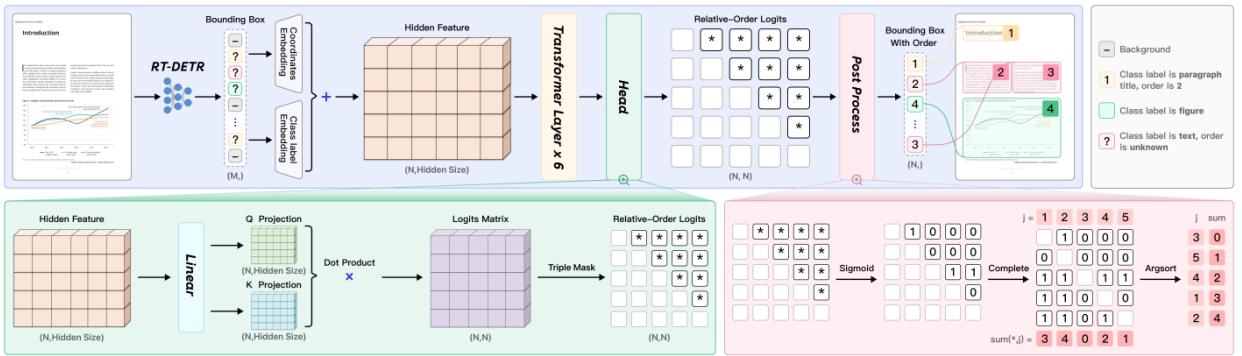 图3:版面分析模型架构
图3:版面分析模型架构
- 检测器(RT-DETR):用于定位和分类元素。RT-DETR作为实时检测模型,速度快且精度高。
- 排序网络(Pointer Network):这是点睛之笔。传统的检测模型只给框,不给顺序。而文档的阅读顺序(Reading Order) 对于RAG至关重要。PP-DocLayoutV2 引入了一个轻量级的指针网络,显式地对检测到的元素进行几何关系建模,预测出符合人类阅读习惯的顺序。
这种分离设计,使得模型可以用较低的分辨率快速处理版面结构,避免了VLM处理高分辨率大图时的算力浪费。
2. 元素识别:PaddleOCR-VL-0.9B —— 小身材,大能量
这是整个系统的核心。为了在资源受限的环境下实现极致的识别效果,团队构建了一个仅有 0.9B(9亿参数) 的视觉语言模型。
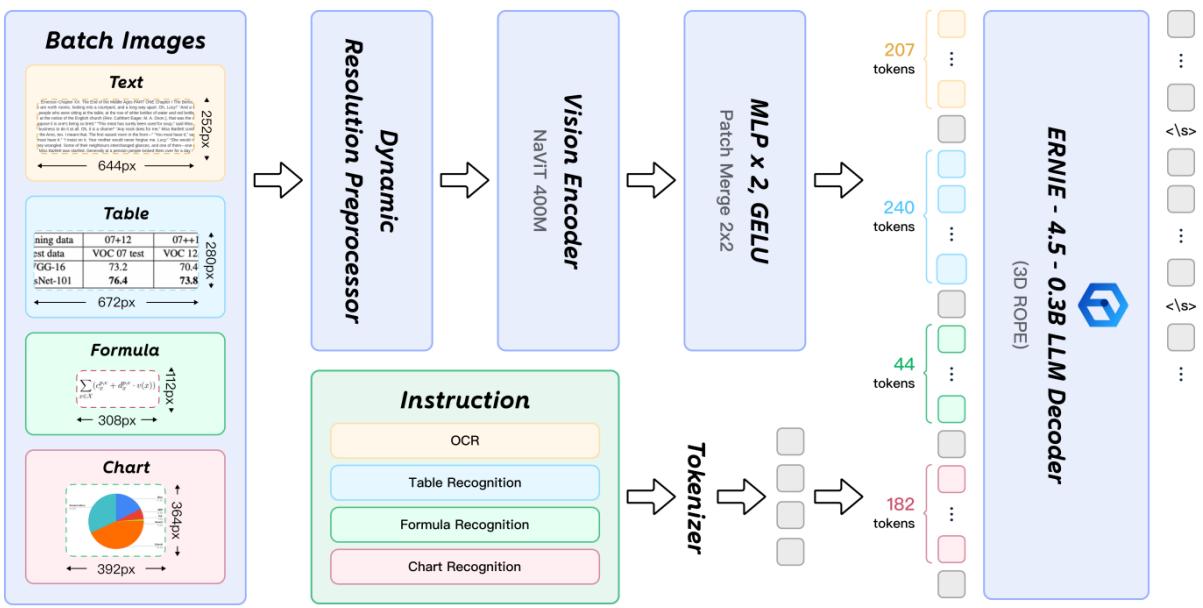 图4:PaddleOCR-VL-0.9B 的模型架构
图4:PaddleOCR-VL-0.9B 的模型架构
这个模型的设计充满了对OCR任务特性的深刻理解:
- 视觉编码器(NaViT-style):这是关键创新。传统的VLM往往需要将图片缩放或填充到固定分辨率(如224x224或336x336),这会导致细长文本行或高长宽比的文档变形、模糊。PaddleOCR-VL 采用了 NaViT(Native Aspect Ratio ViT) 风格的编码器,支持动态高分辨率输入。这意味着,无论文档是横屏还是竖屏,模型都能以“原生”清晰度进行处理,极大减少了因图像压缩导致的识别错误。
- 语言模型(ERNIE-4.5-0.3B):为了极致的推理速度,团队选择了百度自研的超轻量语言模型 ERNIE-4.5-0.3B。虽然参数少,但配合3D-RoPE位置编码,它在OCR这种“看图说话”的特定任务上表现出了惊人的解码效率。
💡 洞见: 这种“强视觉(动态高分)+ 轻语言(0.3B)”的组合,完美契合了OCR任务的本质——OCR更多依赖于视觉感知的精细度,而非复杂的逻辑推理。这是PaddleOCR-VL能够以小胜大的关键。
📊 数据工程:3000万高质量数据的炼金术
在多模态领域,Data is all you need。PaddleOCR-VL 的成功离不开其背后庞大且精细的数据工程。团队构建了一套完整的高质量数据构建管线。
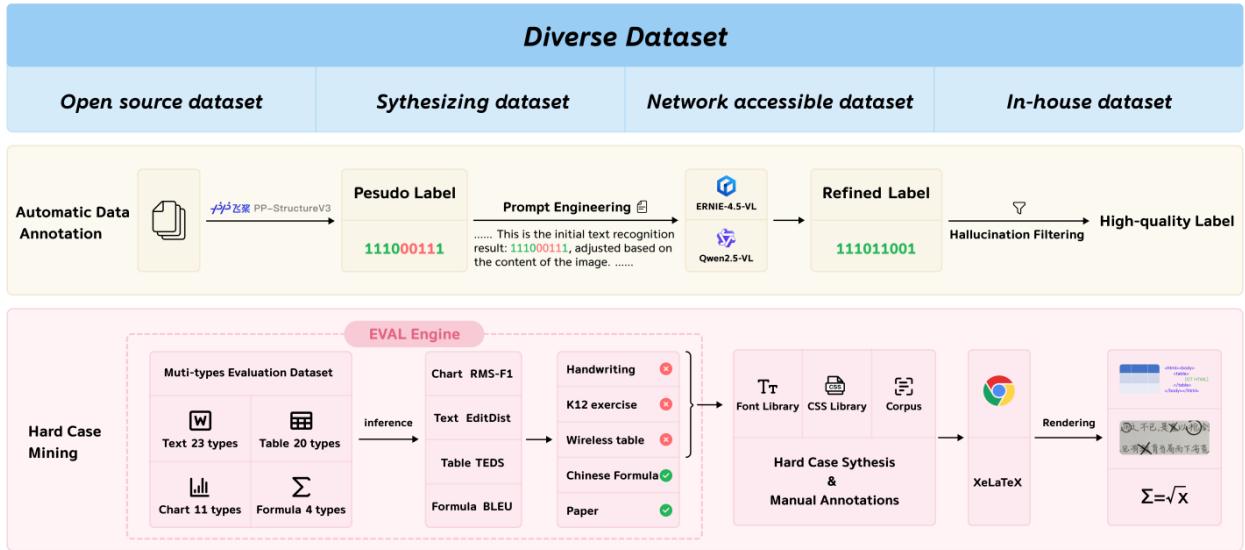 图5:PaddleOCR-VL-0.9B 训练数据的构建流程
图5:PaddleOCR-VL-0.9B 训练数据的构建流程
1. 海量数据源汇聚
团队收集了超过 3000万 训练样本,来源极其丰富:
- 开源数据集:涵盖文本(CASIA-HWDB)、公式(UniMER-1M)、图表(ChartQA等)。
- 数据合成:针对稀缺数据类型进行大规模合成,平衡数据分布。
- 网络爬取:包括论文、报纸、手写扫描件、试卷等真实场景数据,增强模型的鲁棒性。
- 内部积累:PaddleOCR多年积累的独家数据。
2. 自动化标注与“蒸馏”
面对如此庞大的数据,人工标注是不可能的。团队采用了一种级联标注策略:
- 先用专家模型(PP-StructureV3)生成伪标签。
- 再利用更强大的多模态大模型(ERNIE-4.5-VL, Qwen2.5-VL)结合Prompt工程进行“精修”。
- 最后通过幻觉过滤机制清洗数据。
这实际上是一种知识蒸馏的过程,将顶尖大模型的能力“压缩”进了0.9B的小模型中。
3. 困难样本挖掘(Hard Case Mining)
这是提升SOTA性能的临门一脚。团队建立了一个细粒度的评估引擎,专门针对模型表现差的类别(如复杂公式、密集表格、生僻字)进行定向挖掘和合成。哪里不会补哪里,这种针对性的训练策略极大地提升了模型的短板。
🏆 实验结果:全方位SOTA,吊打大参数模型
PaddleOCR-VL 的实测表现如何?可以用“惊艳”来形容。
1. 综合文档解析能力(Page-level)
在权威的 OmniDocBench v1.5 评测中,PaddleOCR-VL 取得了 92.86 的综合高分,稳居第一。
- 对比 Pipeline 工具:大幅超越 Marker、MinerU 等知名工具。
- 对比 通用 VLMs:令人震惊的是,0.9B的 PaddleOCR-VL 在文档解析任务上,击败了 GPT-4o (75.02)、Qwen2.5-VL-72B (87.02) 和 InternVL3.5-241B (82.67)。
- 对比 专用 VLMs:优于 MinerU2.5、Got-OCR 等同类竞品。
这意味着,在文档解析这个垂直领域,专用的小模型完全可以战胜通用的超大模型,而且成本要低得多。
2. 细粒度元素识别(Element-level)
- 文本识别:在多语言测试中,支持109种语言,无论是拉丁语系还是中文、日文、阿拉伯文,PaddleOCR-VL 的编辑距离(Edit Distance)都显著低于对比模型。特别是在手写体、竖排文本等困难场景下,优势巨大。
- 表格识别:表格结构还原是OCR的噩梦。PaddleOCR-VL 在表格TEDS指标上达到了 90.89,展现了对复杂表格结构的深刻理解。
- 公式与图表:无论是行内公式还是复杂的图表转Markdown,模型都表现出了极高的准确率。
3. 推理速度与效率
除了准,还要快。得益于0.9B的超小参数量,PaddleOCR-VL 的推理延迟极低,吞吐量远超基于7B或72B模型的方案。这使得它非常适合在边缘设备或大规模服务器集群中进行低成本部署。
📝 总结与思考:文档解析的新范式
PaddleOCR-VL 的发布,不仅仅是提供了一个新的SOTA模型,更给我们带来了关于AI落地的深刻思考:
- “大”不一定就是好:在特定垂直领域(如文档解析),精心设计的轻量级模型架构 + 高质量的领域数据,完全可以击败参数量大百倍的通用模型。这为企业降低AI落地成本指明了方向。
- 视觉感知的回归:NaViT架构的应用再次证明,对于细粒度识别任务,输入的视觉分辨率和宽高比至关重要。盲目压缩图像是OCR性能的杀手。
- RAG的基石:随着RAG技术的普及,文档解析的质量直接决定了知识库的质量。PaddleOCR-VL 提供的精准阅读顺序和结构化输出,将极大提升RAG系统回答问题的准确性。
PaddleOCR-VL 是百度PaddlePaddle团队在OCR领域深耕多年的集大成之作。它不仅是一个模型,更是一套高效、实用、低成本的文档数字化解决方案。对于开发者和企业而言,这是一个不容错过的强大工具。
🔍 开源地址与Demo:
- GitHub: https://github.com/PaddlePaddle/PaddleOCR
- HuggingFace: https://huggingface.co/PaddlePaddle
本文基于论文 "PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model" 解读。