Appearance
腾讯混元团队推出HunyuanOCR:重新定义轻量级OCR新标准
1B参数吊打4B模型?腾讯混元视觉团队打造业界最强开源OCR
在人工智能技术飞速发展的今天,光学字符识别(OCR)已经成为数字化转型的基础设施。从银行票据处理到医疗档案电子化,从街头路牌翻译到课堂板书提取,OCR技术的身影无处不在。然而,尽管市场需求旺盛,传统OCR系统却长期面临着一个尴尬的局面:要么依赖复杂的级联流水线导致错误累积,要么使用通用视觉语言模型导致推理成本居高不下。
今天,一个来自腾讯混元视觉团队的重磅发布,或许将彻底改变这一格局。
HunyuanOCR,一款仅用1B参数就实现了全面超越的开源OCR模型,不仅在多项基准测试中吊打了包括Qwen3-VL-4B在内的更大参数模型,更在ICDAR 2025 DIMT挑战赛中一举夺得小模型赛道冠军。这意味着什么?意味着企业级OCR应用不再是只有财大气粗的科技巨头才能玩得转的领域,轻量级、高性能、低成本的OCR解决方案已经真正可行。
今天,我们就来深度解析这项来自腾讯混元视觉团队的工作,看看他们是如何用不到10亿参数实现对数十亿参数模型的全面超越的。
一、OCR技术的演进:从流水线到端到端的艰难求索
1.1 传统OCR系统的困境
要理解HunyuanOCR的创新价值,我们首先需要回顾OCR技术的发展历程。
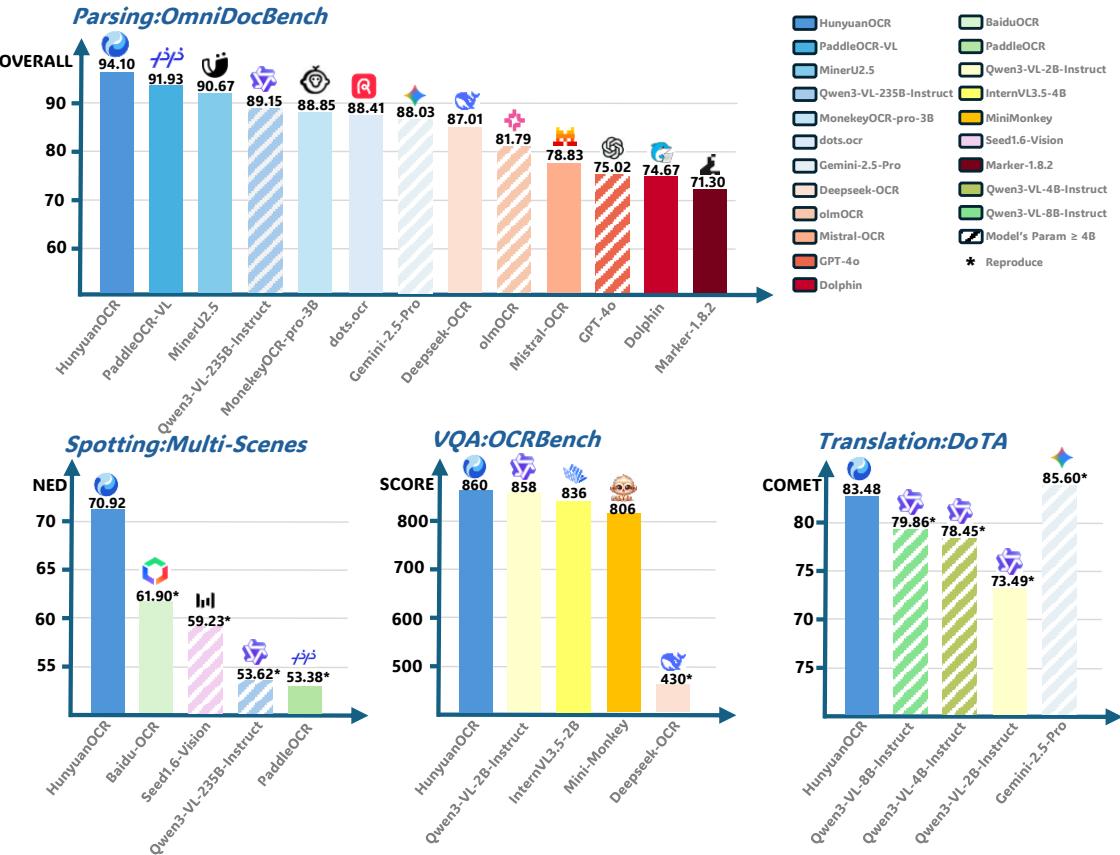 图1:HunyuanOCR与其他SOTA模型的性能对比
图1:HunyuanOCR与其他SOTA模型的性能对比
回溯到上世纪90年代,传统OCR系统普遍采用高度模块化的流水线架构。一个完整的文档解析系统往往需要整合至少五个关键子系统:文本检测模块、多语言文本识别引擎、细粒度布局分析组件、专用数学公式识别单元,以及结构化表格识别模块。这种设计虽然提高了系统的灵活性和可优化性,但同时也埋下了两大隐患。
第一是错误级联传播。在级联处理流程中,前一阶段的误差会不断累积放大。文本检测的微小偏差会导致后续识别模块输入质量下降,布局分析的错误可能造成文本块顺序错乱。这些早期的小问题经过层层传递,最终会严重影响到系统输出的准确性和可用性。
第二是高维护成本。每个独立模块都需要专门的团队进行调优和更新,当业务场景变化或新增支持语言时,修改任何一个环节都可能引发连锁反应。这对于追求快速迭代的企业来说无疑是噩梦。
近年来,虽然视觉语言模型(VLM)技术取得了突破性进展,一些专门的OCR模型如MonkeyOCR、Dots.OCR、MinerU2.5等相继问世,但它们大多仍采用"两阶段"设计——先用一个独立的布局检测模型定位文档元素,再用VLM解析各个区域的内容。这种混合架构虽然在一定程度上提升了精度,却依然无法完全摆脱布局分析阶段错误传播的困扰,更没有充分发挥端到端联合推理的潜力。
1.2 通用VLM的尴尬定位
你可能会问,既然通用视觉语言模型已经如此强大,为什么不直接用它们来做OCR?
这个问题问得好。确实,以Gemini、QwenVL为代表的通用VLM展现出了相当不错的文字感知能力,能够准确识别印刷体和手写体文字,还能处理复杂布局、低分辨率图像和多语言内容。但实际应用中存在两个难以回避的痛点。
首先是推理成本。这些大家伙的参数规模动辄几十亿甚至上百亿,推理需要海量的GPU显存和算力支持。以Qwen3-VL-235B为例,光是加载模型就需要配备顶级GPU的服务器,对于大多数中小企业来说,这运维成本简直是天方夜谭。
其次是延迟问题。在实际的商业场景中,OCR服务往往需要秒级甚至毫秒级响应。通用VLM虽然能力出众,但在实时性要求高的场景下往往力不从心。想象一下,用户拍照上传一张发票,系统需要等待十几秒才能返回结果——这体验谁受得了?
于是,一个核心矛盾摆在了所有OCR从业者面前:如何在保证性能的前提下实现轻量化?如何在降低成本的同时不牺牲精度?
腾讯混元视觉团队交出的答卷,就是HunyuanOCR。
二、HunyuanOCR架构解密:大道至简的端到端设计
2.1 整体架构:三个核心组件的精妙配合
 图2:HunyuanOCR架构图——端到端框架集成了原生分辨率视觉编码器、自适应MLP连接器和轻量级语言模型
图2:HunyuanOCR架构图——端到端框架集成了原生分辨率视觉编码器、自适应MLP连接器和轻量级语言模型
HunyuanOCR的架构设计堪称精妙——它没有追求复杂的技术堆砌,而是用最简洁的方式实现了最高效的端到端处理。整个系统由三大核心模块组成:
1. 原生分辨率视觉编码器(Hunyuan-ViT)
这个模块基于SigLIP-v2-400M预训练模型构建,采用了一种创新的混合生成-判别联合训练策略,显著增强了模型对复杂视觉语义的理解能力。
最令人称道的是它的原生分辨率支持机制。传统ViT在处理图像时往往需要将图像Resize到固定分辨率,导致长文本文档被强制压缩变形,大量细节信息丢失。而Hunyuan-ViT通过自适应分块机制,能够根据输入图像的原始长宽比进行分块处理,保留完整的原始信息。这对于长文本行、宽幅文档、低质量扫描等极端情况尤其友好,文字识别准确率得到显著提升。
2. 自适应MLP连接器
这个模块是视觉编码器和语言模型之间的桥梁,扮演着"翻译官"的角色。它的核心工作是将视觉编码器输出的高分辨率特征图进行空间维度自适应的内容压缩,在有效减少Token序列长度的同时,关键的语义信息——尤其是文字密集区域的信息——被完好保留。